End-to-end Neural Coreference Resolution(Kenton Lee et al, 2017) EMNLP
기존의 Coreference Resolution은 mention detection을 먼저 진행한 후 mention clustering을 진행하는 방식이었다. 하지만 이 논문에서는 이러한 pipeline을 건너뛴 end-to-end model을 처음으로 소개한다.
Terminology
span : 한 개 이상의 단어로 이뤄진 명사구가 될 가능성이 있는 단어들의 집합
mention : 상호참조해결의 대상이 되는 모든 명사구
head : mention에서 해당 구의 실질적인 의미를 나타내는 단어이며 중심어라고 불림
End-to-End 모델을 가능케한 KEY IDEA는?
1. 모든 span을 잠재적 mention으로 본다.
2. 각 mention에 대한 가능한 선행사(Antecedent)의 분포를 학습한다.
이 논문에서는 end-to-end neural model을 이용하여 어떤 span이 entity metion이 되고 어떻게 동일한 의미의 entity metion을 clustering 할지를 한번에 학습한다.
Task Idea
길이가 다른 모든 가능한 span을 만든다. 만약 D라는 document에 T개의 단어가 있다면, 가능한 span의 개수는
N = T(T+1) / 2 가 된다.
하나의 다큐먼트에는 i개의 Span이 생성될 수 있다. (1 ≤ i ≤ N)
i번째 span의 시작 단어인 START(i)에 근거하여 span의 순서를 정한다.
동일한 START(i)를 가진 스팬은 END(i)에 의해 순서가 정해지게 된다.
각 span i 에는 선행사 yi가 할당된다.
yi에 대해 가능한 선행사 집합 = Y(i) = {ϵ , 1 , . . . i - 1}
ϵ는 더미 선행사이다.
span i의 TRUE 선행사 span j (1 ≤ j ≤ i - 1)는 i와 j 사이의 coreference 링크를 나타낸다.


더미 선행사 ϵ가 가능한 두 가지 시나리오는 :
(1) span i는 entity mention이 아니다.
(2) span i는 entity mention이지만 선행사가 없다.
이러한 방식으로 일련의 선행사를 예측하고 연결된 모든 범위를 그룹화하여 최종 군집을 수행한다.
Model
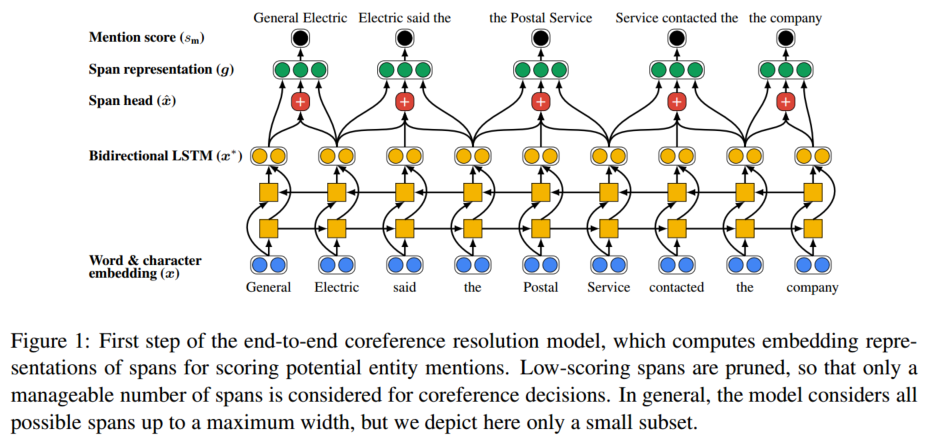
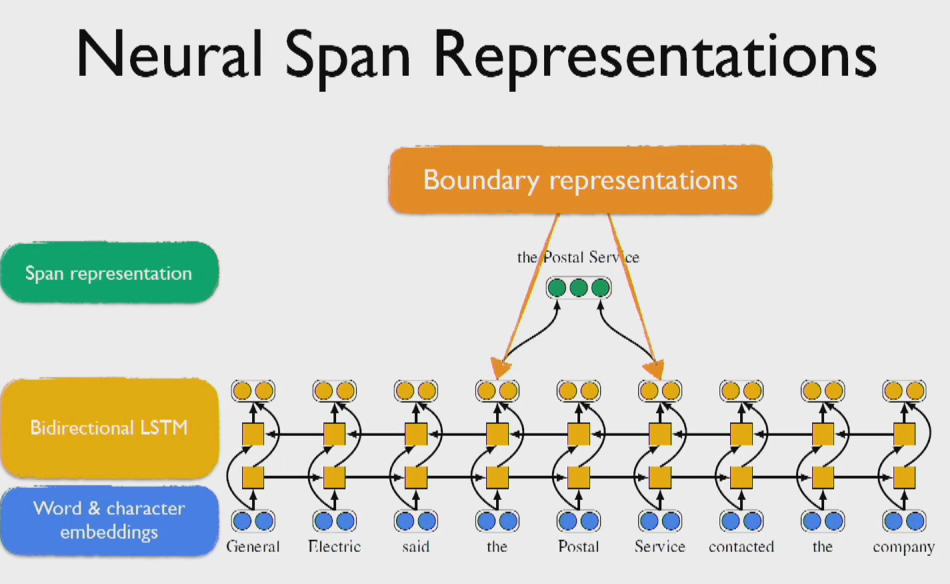
1. span embedding representation을 계산한다. 이는 bidirectional LSTM을 이용한다.

2. span 내의 단어들의 attention을 이용하여 span head를 구한다.

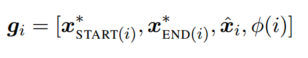
gi는 boundary representation인 x∗ START(i) 와 x∗ END(i)를 포함한다.
또한 soft head word vector xˆi 와 feature vector φ(i)를 span i의 사이즈로 임베딩한 값도 포함한다.
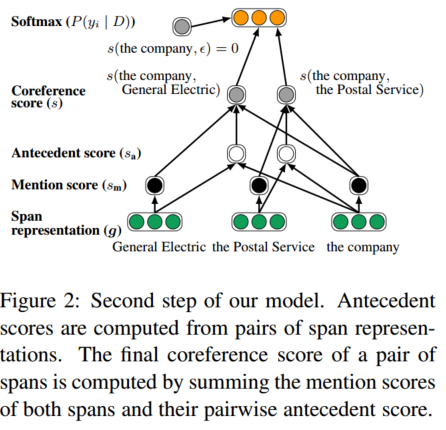
3. 아래의 식을 이용해 mention score를 계산하고, 이 score가 낮은 span에 대한 프루닝을 진행한다. (top λ*N을 이용하는데, 여기서 람다는 하이퍼 파라미터이다.)

* number of pairwise computations을 줄이기 위해 mention score가 충분히 높은 span들만을 coreference decision 단계에서 이용한다.
4. span들의 pair들을 이용하여 antecedent score를 계산한다.


5. Span Ranking Model : pair가 되는 각 span의 mention score들과 pairwise antecedent score를 종합하여 coreference score를 계산한다. 그리고 이를 maximize하도록 학습한다.

아래의 Figure는 위의 과정을 쉽게 나타낸 것이다.
Learning
학습방법은 이러하다. gold clustering 안에 있는 모든 정확한 선행사들의 marginal log likelihood를 maximize하며 optimizing한다.
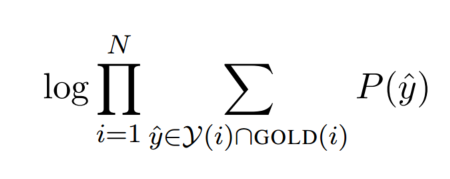
GOLD(i)는 span i를 포함하고 있는 gold cluster를 의미하며, span i가 선행사가 없을 경우 혹은 gold cluster에 포함되지 않을 경우 GOLD(i)={ϵ}과 같이 설정된다. 해당하는 objective function을 최적화하는 것으로 span들은 올바르게 pruning된다. pruning이 처음에는 무작위방식이지만, 학습이 진행될수록 positive update하게 된다.
Experiment
OntoNotes(CoNLL-2012)
2802 documents(longest document has 4009 words)
Result




