Higher-order coreference resolution with coarse-to-fine inference(Kenton Lee et al, 2018)
1. Introduction
저자의 이전 논문 "End-to-End Neural Coreference Resolution"에서는 각 mention에 대해 선행하는, pair가 되는 mention들에 대해서만 score가 계산되었다(이전 글을 확인해보자). 그리고 mention pair 사이의 coreference link는 다른 link들의 영향을 받지 않고 독립적으로 결정되었다. 따라서 이는 cluster가 locally consistent 하지만 globally inconsistent하다는 문제를 발생시켰다. 예를들면 아래와 같은 문제가 발생하는 것이다.
[you]의 경우 복수와 단수의 의미를 모두 내포할 수 있다. 따라서 [I]와 [all of you] 둘 다와 국소적으로 호환된다. 하지만 이들을 하나의 클러스터로 묶었을 때는 복수적, 단수적 의미가 모두 포함되므로 비일관성이 발생한다. 이전 논문의 경우 [all of you]는 [you]와 클러스터링되고 [you]는 [I]와 클러스터링된다. 그리고 이 두 링크들은 서로 독립적이기 때문에 이 셋은 하나의 클러스터로 묶이게 되었다. 하지만 실제로는 [you, I], [ϵ, all of you]로 클러스터링 되어야 한다.


본 논문에서는 span-ranking architecture모델을 베이스라인으로 이용하되 이러한 문제를 해결하기 위한 higher-order inference를 제시한다.
매 iteration 마다 antecedent distribution은 span representation을 계산할 때 어텐션으로 이용되도록 하여, 이번의 coreference decision이 다음번의 coreference decision에 영향을 주도록 하는 것이다. 예를들어 [I, you] 의 coreference link가 [you, all of you]의 coreference link에 영향을 미치는 것이다.
그리고 이러한 모델의 computational challenge를 줄이기위해 coarse-to-fine 방식을 제시하며 이는 end-to-end 모델을 학습하는 과정에서 같이 학습될 것이다. 이를 이용하면 프루닝이 더 많아지고 계산할 선행사의 수를 줄일 수 있다.
2. Background
Task Definition
이전 논문 "End-to-End Neural Coreference Resolution"과 마찬가지로 주어진 문서에 등장하는 span i에 대해 각 antecedent(yi)들을 태깅한다.
yi에 대해 가능한 antecedent set들은 다음과 같다: Y(i)={ϵ,1,...,i−1}
* ϵ은 antecedent가 없을 경우를 뜻한다.
antecedent가 없을 경우는 다음 시나리오들 중 하나를 의미한다:
(1) 해당 span i가 entity mention이 아니거나
(2) span i가 entity mension이지만 선행하는 span이 없는 경우
이러한 방식으로 metion과 antecedent mention들의 클러스터링을 수행한다.
Baseline Model
이전 논문에서 나온 모델을 베이스라인으로하며, 아래는 이 베이스라인에 대한 설명이다.
목표는 각 span i에 대한 antecedent들의 확률 분포 P(yi)를 학습하는 것이다:
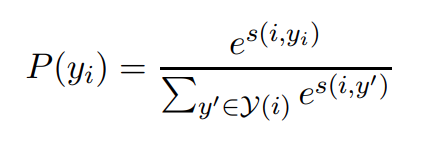
이 때, s(i,j)는 span i와 span j 사이의 coreference link score를 의미한다.
이 score는 다음과 같이 구성된다:

이 때 sm(i)와 sm(j)는 각 span i와 span j가 mention인지에 대한 점수를 뜻하고 sa(i,j)는 j가 i의 antecedent 일 때의 점수를 뜻한다.
이러한 점수는 vector repregentation gi를 통해 계산된다. 이는 bidirection LSTM을 이용하여 구하게 되는데 그 식은 다음과 같다:

여기서 ∘는 element-wise multiplication을 의미하고 FFNN은 feed-forward neural network를 의미한다. ϕ(i,j)는 두 span사이의 거리나 메타데이터에서 사용되는 feature 정보(i.e. 장르)를 압축한 feature vector이다.
3. Higher-order Coreference Resolution
위의 베이스라인 모델은 introduction에서 말했듯이 문제가 존재한다. 따라서 이를 해결하기 위한 방법을 이 논문에서는 제시한다. 핵심은 여러 번의 iteration을 통해 span i 와 선행사들 사이의 확률분포를 생성하고 이를 attention으로 이용하는 것이다.

attention mechanism은 아래와 같다:

이는 attention mechanism에서 사용될 값이 확률 분포에 기반하여 생성된다는 것을 확인할 수 있다.
이러한 span representation은 다음과 같이 업데이트 된다.

이 때 학습된 gate vector fni는 현재 span information을 얼마나 유지하고, 얼마나 새로운 정보를 융합할지를 의미한다.
즉, span i에 대해 가질 수 있는 antecedent들에 대한 ratio를 학습하는 것이다. 이 때 ratio는 antecedent가 높은 확률(점수)를 가질 경우 높게 계산되어 해당 span representation이 더해지게 된다. 이후, 점차 antecedent들의 정보와 현재 span의 정보들이 융합되어 새로운 span representation을 만드는 것이다.
4. Coarse-to-fine Inference
이러한 모델들의 문제점은 바로 학습시간이다. 너무 긴 문서 같은 경우에 pruning을 사용하지 않으면 span이 너무 많아 bottlenect 현상이 발생하였다. 즉 tensorsize M×M×(3|g|+|ϕ|)에 대해 계산을 하였기에 antecedent들을 pruning하는 방법이 필요했다.
따라서 기존 논문에서는 휴리스틱하게 가장 가까운 K개의 antecedent만 고려하여 계산량을 다음과 같이 줄였다:
M×K×(3|g|+|ϕ|)
하지만 이는 매우 긴 문서에 대해 성능 저하를 일으켰다.
본 논문에서는 이 문제를 coarse-to-fine inference를 통해 해결하려한다.
이를 해결하기 위해 먼저, span i와 span j에 대해 간단한 score function을 만들었다:

Wc는 학습된 weight matrix로, 이는 span i와 span j를 단순 비교할 수 있도록하는 함수이다. Similarity를 이용해 pruning을 하는 것이라고 생각하면 편할 것이다.

이 sc(i,j)는 likely antecedent들을 계산하고 three stage beam pruning step으로서 이용된다:
1) sm(i)에 기반하여 top M개의 span을 추출한다.
2) sm(i)+sm(j)+sc(i,j)에 기반하여 span i에 대해 top K개의 antecedent들을 추출한다. 주의할 점은 sa(i,j)가 아니라 간단한 상호참조점수 함수를 통해 추출한다는 것이다.
3) 이 후 남아있는 span pairs에 대해 s(i,j)를 계산한다. 이 마지막 단계에서 soft higher-order inference가 계산되게 된다.
*beam 탐색 :
- 각 후보 시퀀스는 가능한한 모든 다음 스텝들에 대해 확장된다.
- 각 후보는 확률을 곱함으로써 점수가 매겨진다.
- 가장 확률이 높은 시퀀스가 선택되고, 다른 모든 후보들은 제거된다.
- 위 절차들을 시퀀스가 끝날때까지 반복한다.
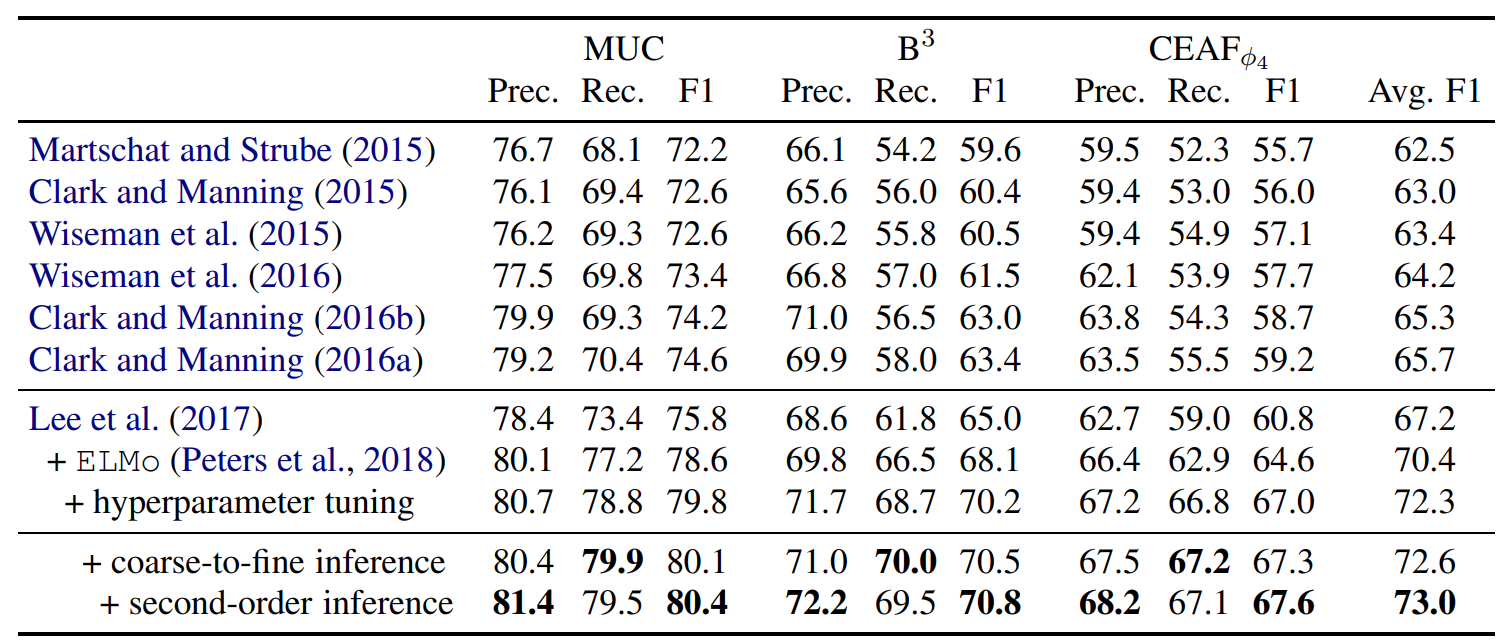
5. Experimental Setup
이 논문에서는 임베딩 방식으로 ELMO와 GLOVE를 사용하였다.
6. Results