BERT for Coreference Resolution : Baselines and Analysis(Mandar Joshi et al, 2019)
c2f-coref model(Lee et al, 2018)에 ELMO 대신 BERT를 적용시킨 논문으로 Coreference Resolution을 태클한다.
1. Introduction
BERT 모델은 다양한 task에서 sota를 달성하는 모델의 backbone으로 이용된다. 이 모델에서는 BERT와 "Higher-order coreference resolution with coarse-to-fine inference"(Kenton Lee et al, 2018)의 c2f-coref모델(본 논문에서 붙인 명칭)을 겹합하여 coreference resolution을 해결하고자 한다. 즉, 원래 Kenton Lee가 이용한 ELMO + GLOVE 모델을 BERT로 대체한 것이다.
2. Overview of c2f-coref
이전 논문정리(Higher-order coreference resolution with coarse-to-fine inference)에 있으니 그걸 보자.
3. Applying BERT
1. ELMO와 GloVe를 BERT로 대체한다.
2. 첫번째와 마지막 word-pieces를 span representations으로 본다.
3. 다큐먼트의 segment는 max_segment_len 하이퍼파라미터로 나뉜다.
4. 기존의 BERT는 최대 512개의 word-piece의 시퀀스에 대해 훈련된다. 이러한 변형된 input은 여러 단점을 가진다. 그중 하나는 여러 개의 세그먼트로 이루어진 문서(512 토큰을 넘어가는 문서)를 처리할 때 세그먼트의 시작이나 끝에 있는 토큰의 경우 이들을 제대로 represent하는 vector를 만드는 것이 제한된다는 것이다. 따라서 아래와 같은 방식으로 BERT의 input에 대한 변형을 진행한다:
기존의 BERT가 이용하는 독립적 변형( independent variant) vs 중복적 변형(overlap variant)
- 독립적 변형 : 독립된 인스턴스(instance)로 작용하는 non-overlapping 세그먼트를 사용한다. 각 토큰의 representation은 해당 세그먼트에 있는 단어 집합으로 제한된다.
- 중복적 변형 : T/2 번 째 토큰마다 T 크기 세그먼트를 만들어 문서를 overlapping 세그먼트로 분할한다. 그런 다음 이들 세그먼트는 독립적으로 BERT 인코더에 전달되며, 최종 token representation은 두 개의 중복 세그먼트의 representation에서 element-wise interpolation으로 도출된다.

4. Experiment & Result
데이터셋 : OntoNotes(English) from CoNLL-2012
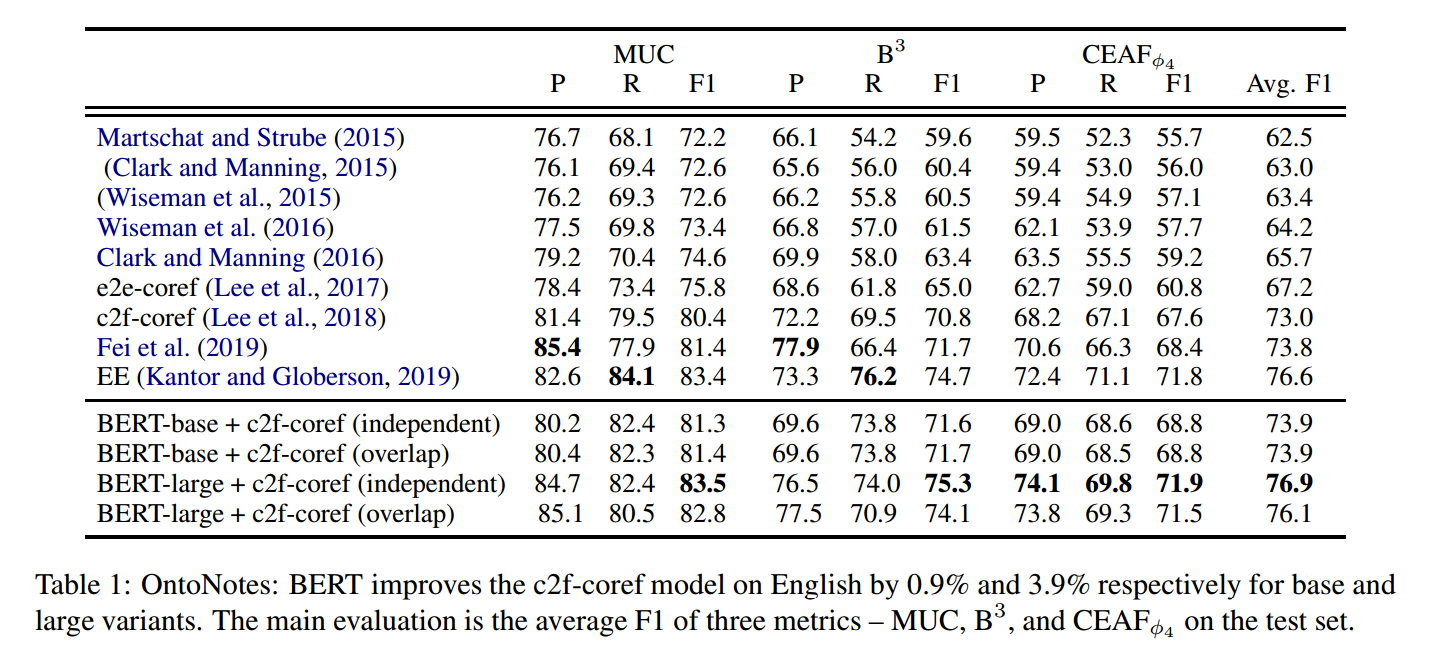
BERT-base, BERT-large > ELMo-based c2f-coref model
overlap variant가 independent variant보다 좋은 점은 찾지 못했다.



