SpanBERT : Improving Pretraining by Representing and Predicting Spans - Mandar Joshi et al, 2020
현재 Coreference Resolution분야에서 OntoNotes Benchmark에 대해 SOTA인 SpanBERT
SpanBERT는 BERT large와 동일한 데이터로 학습되며, 파라미터의 개수도 동일하다. 하지만 기존의 BERT보다 Question Answering과 Coreference Resolution 등 여러 TASK에 효과적이다.
BERT는 token을 masking한 뒤 masking된 token을 예측하는 방식의 self-supervised pretraining을 진행했다.
하지만 SpanBERT는 spans of text를 예측하는 것을 목적으로 하기 때문에 좀 다른 self-supervised pretraining을 진행한다.
우선 기존처럼 random token을 masking하기보다는 contiguous random spans를 masking한다.
그리고 Span-Boundary Objective(SBO)를 이용해 masking된 span 전체를 그 경계 토큰으로부터 유추하며 span의 boundary를 학습한다. 이 SBO를 이용해 span-level의 정보를 boundary tokens에 저장한다.
또한, 2개가 아닌 하나의 segment를 pretraining하고 NSP를 제외한다(이렇게하면 성능이 더 높아진다고 한다).

Model
기존의 BERT를 기반으로 하지만 여러 차이점들이 있다.
1. Span Masking - token을 random하게 masking하는 BERT와 달리 span을 random하게 masking한다.
2. Span Boundary Objective(SBO) - span의 boundary token들을 이용하여 전체 masked span을 예측한다.
3. 기존의 BERT는 [SEP]을 이용해 나누어진 두개의 segment를 인풋으로 받고 NSP를 진행한다면, SpanBERT는 하나의 contiguous segment를 인풋으로 받고 NSP는 하지않는다.
1. Span Masking
하나의 segment를 이루는 token들 중 15%가 masking되는데, 이 masking되는 token들은 sequential하다.
Span의 길이는 geometric distribution(l ∼ Geo(p))에 의해 정해지며, 이는 짧은 span쪽으로 skew되어있다. 이는 아래의 그림을 보면 확인가능하다. 또한, span의 길이는 subword tokens이 아닌 complete word단위가 기준이다.
Span의 시작점은 랜덤하게(uniformly) 선택된다.
SpanBERT는 BERT와 마찬가지로 전체 토큰 중 15%를 masking하지만 individual token에 대한 masking이 아닌 sequential한 span 내의 토큰들만 masking을 적용한다.

2. Span Boundary Objective(SBO)
SpanBERT에서는 span을 경계의 토큰을 사용하여 예측하기 위해 SBO를 도입한다. 이는 span의 경계에 위치하는 token들에 최대한 많은 span 내부 컨텐트를 압축하는 것이다.
예를 들어 span이 x2~x7까지 있다면 x1과 x8을 이용해 이 span을 예측하는 것이다.
우선, 타겟 토큰의 positinoal embedding(pi)과 boundary token의 인코딩(xs−1,xe+1)을 이용하여 output vector인
yi를 구하게 된다.

위의 식에서 f(.)는 아래와 같다.
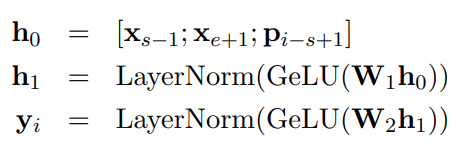
최종적으로는 span boundary loss와 mlm loss가 합해지고 이를 최종 LOSS로 이용하여 학습을 진행한다.

3. Single-Sequence Training
BERT의 경우 sequential한 두 개의 문장을 인풋으로 하여 모델이 NSP를 수행하도록한다. 그러나 NSP가 오히려 정확도를 떨어진다고 한다. 오히려 single sequence를 인풋으로 받고 NSP를 제외하는 것이 결과가 좋았다는 것이다.
이 논문에서는 NSP를 진행하는 것보다 차라리 하나의 긴 context (a single contiguous segment of up to n = 512 tokens)를 보는 것이 이득이라고 주장한다.
또한, 오히려 NSP를 하려다가 관계가 없지만 sequential한 문장을 학습해 noise를 추가하는 경우 성능이 저하될 수 있다고 이야기한다.
마무리
기존 버트가 wordpiece 단위로 context를 학습해 임베딩을 진행했다면, 이 모델은 span 단위로 context를 학습해 임베딩을 진행했다고 볼 수 있다. 따라서 다양한 phrase 단위로 의미를 담는 말을 더 잘 represent할 수 있는 모델인 것 같다.
이제 SpanBERT가 Coreference Resolution를 어떻게 태클했는지 확인해보자
블로그에 소개한 논문 중 하나인 BERT for Coreference Resolution : Baselines and Analysis(Joshi et al., 2019)은 higher-order coreference model(Lee et al., 2018)에 BERT(independent version)를 적용해 CR task를 수행한다.
SpanBERT : Improving Pretraining by Representing and Predicting Spans(Mandar Joshi et al, 2020)에서는 동일한 모델에 BERT 대신 SpanBERT를 적용해 coreference resolution을 진행했다. 아래 Table 3는 그 성능을 나타낸다.

이 SpanBERT 위에 올라가는 Coreference Resolution 모델은 이전에 적어놓은 블로그 글들에 자세히 설명되어있다.



